Control Flow¶
Coach is built in a modular way, encouraging modules reuse and reducing the amount of boilerplate code needed for developing new algorithms or integrating a new challenge as an environment. On the other hand, it can be overwhelming for new users to ramp up on the code. To help with that, here’s a short overview of the control flow.
Graph Manager¶
The main entry point for Coach is coach.py.
The main functionality of this script is to parse the command line arguments and invoke all the sub-processes needed
for the given experiment.
coach.py executes the given preset file which returns a GraphManager object.
A preset is a design pattern that is intended for concentrating the entire definition of an experiment in a single
file. This helps with experiments reproducibility, improves readability and prevents confusion.
The outcome of a preset is a GraphManager which will usually be instantiated in the final lines of the preset.
A GraphManager is an object that holds all the agents and environments of an experiment, and is mostly responsible
for scheduling their work. Why is it called a graph manager? Because agents and environments are structured into
a graph of interactions. For example, in hierarchical reinforcement learning schemes, there will often be a master
policy agent, that will control a sub-policy agent, which will interact with the environment. Other schemes can have
much more complex graphs of control, such as several hierarchy layers, each with multiple agents.
The graph manager’s main loop is the improve loop.
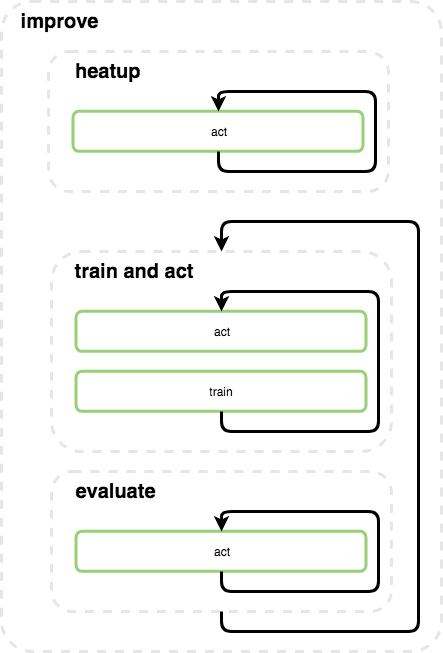
The improve loop skips between 3 main phases - heatup, training and evaluation:
Heatup - the goal of this phase is to collect initial data for populating the replay buffers. The heatup phase takes place only in the beginning of the experiment, and the agents will act completely randomly during this phase. Importantly, the agents do not train their networks during this phase. DQN for example, uses 50k random steps in order to initialize the replay buffers.
Training - the training phase is the main phase of the experiment. This phase can change between agent types, but essentially consists of repeated cycles of acting, collecting data from the environment, and training the agent networks. During this phase, the agent will use its exploration policy in training mode, which will add noise to its actions in order to improve its knowledge about the environment state space.
Evaluation - the evaluation phase is intended for evaluating the current performance of the agent. The agents will act greedily in order to exploit the knowledge aggregated so far and the performance over multiple episodes of evaluation will be averaged in order to reduce the stochasticity effects of all the components.
Level Manager¶
In each of the 3 phases described above, the graph manager will invoke all the hierarchy levels in the graph in a synchronized manner. In Coach, agents do not interact directly with the environment. Instead, they go through a LevelManager, which is a proxy that manages their interaction. The level manager passes the current state and reward from the environment to the agent, and the actions from the agent to the environment.
The motivation for having a level manager is to disentangle the code of the environment and the agent, so to allow more complex interactions. Each level can have multiple agents which interact with the environment. Who gets to choose the action for each step is controlled by the level manager. Additionally, each level manager can act as an environment for the hierarchy level above it, such that each hierarchy level can be seen as an interaction between an agent and an environment, even if the environment is just more agents in a lower hierarchy level.
Agent¶
The base agent class has 3 main function that will be used during those phases - observe, act and train.
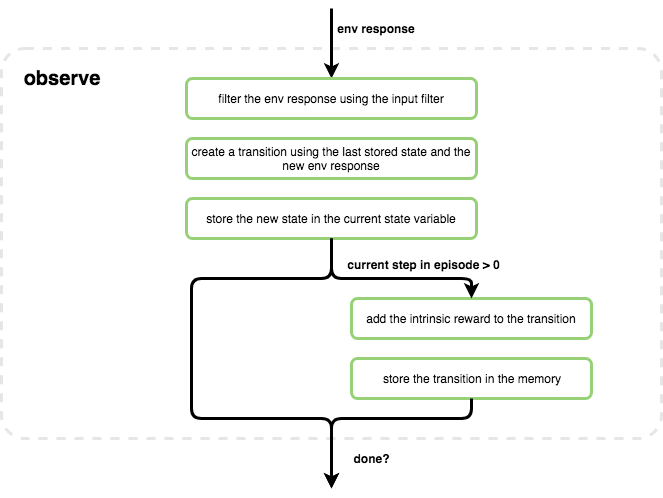
Observe - this function gets the latest response from the environment as input, and updates the internal state of the agent with the new information. The environment response will be first passed through the agent’s
InputFilterobject, which will process the values in the response, according to the specific agent definition. The environment response will then be converted into aTransitionwhich will contain the information from a single step \((s_{t}, a_{t}, r_{t}, s_{t+1}, \textrm{terminal signal})\), and store it in the memory.
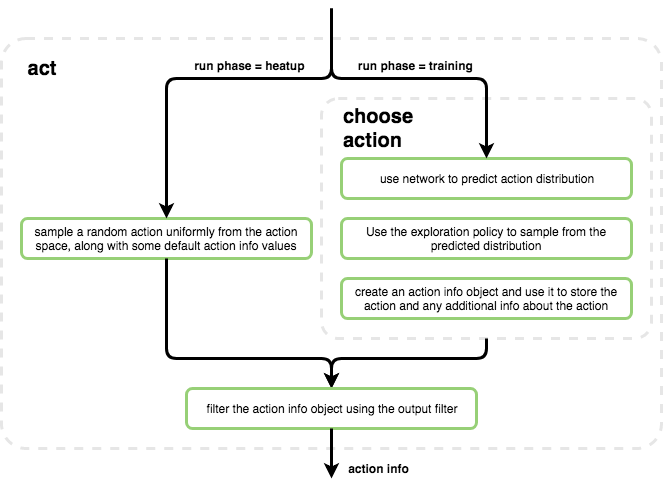
Act - this function uses the current internal state of the agent in order to select the next action to take on the environment. This function will call the per-agent custom function
choose_actionthat will use the network and the exploration policy in order to select an action. The action will be stored, together with any additional information (like the action value for example) in anActionInfoobject. The ActionInfo object will then be passed through the agent’sOutputFilterto allow any processing of the action (like discretization, or shifting, for example), before passing it to the environment.
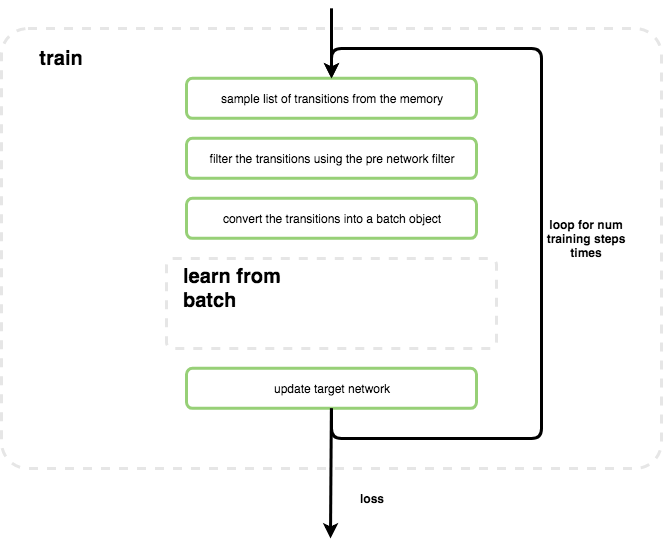
Train - this function will sample a batch from the memory and train on it. The batch of transitions will be first wrapped into a
Batchobject to allow efficient querying of the batch values. It will then be passed into the agent specificlearn_from_batchfunction, that will extract network target values from the batch and will train the networks accordingly. Lastly, if there’s a target network defined for the agent, it will sync the target network weights with the online network.