Hierarchical Actor Critic¶
Actions space: Continuous
References: Hierarchical Reinforcement Learning with Hindsight
Network Structure¶
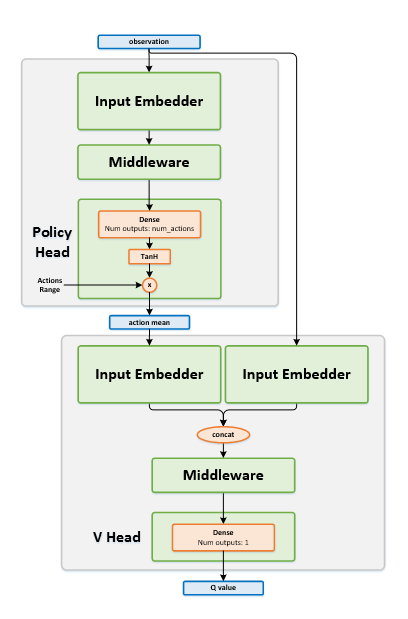
Algorithm Description¶
Choosing an action¶
Pass the current states through the actor network, and get an action mean vector \(\mu\). While in training phase, use a continuous exploration policy, such as the Ornstein-Uhlenbeck process, to add exploration noise to the action. When testing, use the mean vector \(\mu\) as-is.