Intent Extraction
Overview
Intent extraction is a type of Natural-Language-Understanding (NLU) task that helps to understand the type of action conveyed in the sentences and all its participating parts.
An example of a sentence with intent could be:
Siri, can you please remind me to pickup my laundry on my way home?
The action conveyed in the sentence is to remind the speaker about something. The verb remind applies that there is an assignee that has to do the action (who?), an assignee that the action applies to (to whom?) and the object of the action (what?). In this case, Siri has to remind the speaker to pickup the laundry.
Models
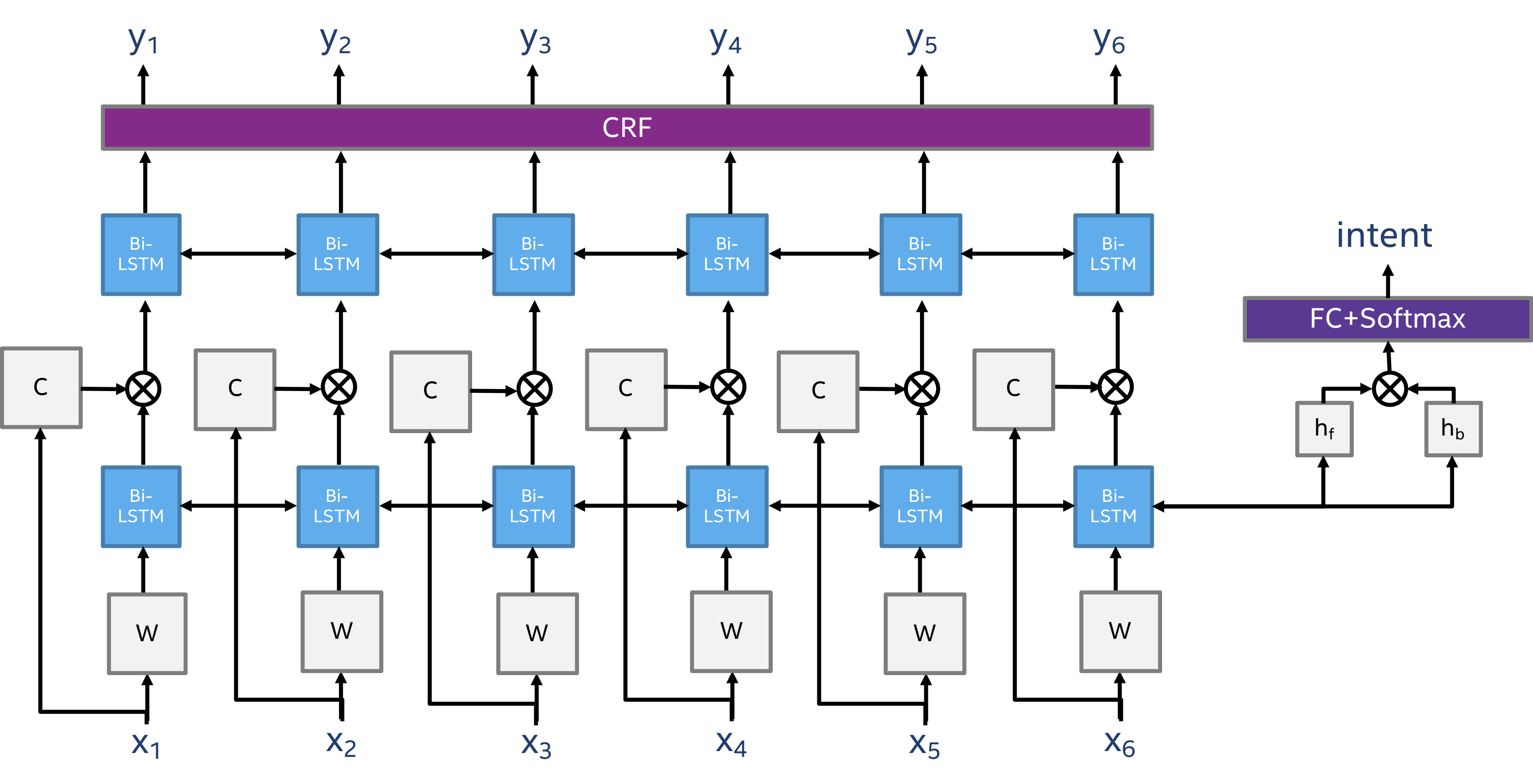
Multi-task Intent and slot tagging model
MultiTaskIntentModel is a Multi-task model that is similar to the joint intent/slot tagging model. The model has 2 sources of input: 1 - words, 2 - characters of words. The model has 3 main features when compared to the other models, character information embedding acting as a feature extractor of the words, a CRF classifier for slot labels, and a cascading structure of the intent and tag classification.
The intent classification is done by encoding the context of the sentences (words x_1, .., x_n), using word embeddings (denoted as W), by a bi-directional LSTM layer, and training a classifier on the last hidden state of the LSTM layer (using softmax).
Word-character embeddings (denoted as C) are created using a bi-directional LSTM encoder which concatenates the last hidden states of the layers.
The encoding of the word-context, in each time step (word location in the sentence) is concatenated with the word-character embeddings and pushed in another bi-directional LSTM which provides the final context encoding that a CRF layer uses for slot tag classification.
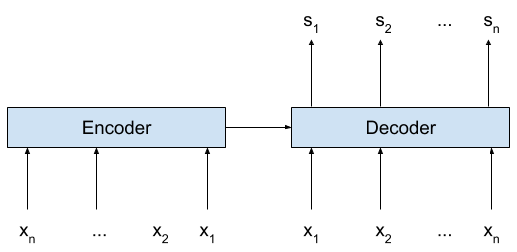
Encoder-Decoder topology for Slot Tagging
The Encoder-Decoder LSTM topology is a well known model for sequence-to-sequence classification.
Seq2SeqIntentModel is a model that is similar to the Encoder-Labeler Deep LSTM(W) model shown in [2].
The model support arbitrary depths of LSTM layers in both encoder and decoder.
Datasets
SNIPS NLU benchmark
A NLU benchmark [5] containing ~16K sentences with 7 intent types. Each intent has about 2000 sentences
for training the model and 100 sentences for validation. SNIPS is a class that loads the dataset from the repository and encodes the data into BIO format. The words are encoded with sparse int representation and word characters are extracted for character embeddings.
The dataset can be downloaded from https://github.com/snipsco/nlu-benchmark, and more info on the benchmark can be found here. The terms and conditions of the data set license apply. Intel does not grant any rights to the data files.
Once the dataset is downloaded, use the following path <SNIPS folder>/2017-06-custom-intent-engines as the dataset path when using SNIPS data loader.
TabularIntentDataset
We provide an additional dataset loader TabularIntentDataset which can parse tabular data in the format of:
- each word encoded in a separate line:
<token> <token_tag> <intent_type> - sentences are separated with an empty line
The dataset loader extracts word and character sparse encoding and label/intent tags per sentence. This data-loader is useful for many intent extraction datasets that can be found on the web and used in academic literature (such as ATIS [3] [4], Conll, etc.).
Files
- examples/intent_extraction/train_enc-dec_model.py: training script to train a
Seq2SeqIntentModelmodel. - examples/intent_extraction/train_mtl_model.py: training script to train a
MultiTaskIntentModelmodel. - examples/intent_extraction/interactive.py: Inference script to run an input sentence using a trained model.
Running Modalities
Training
An example for training a multi-task model (predicts slot tags and intent type) using SNIPS dataset:
python examples/intent_extraction/train_mtl_model.py --dataset_path <dataset path> -b 10 -e 10
An example for training an Encoder-Decoder model (predicts only slot tags) using SNIPS, GloVe word embedding model of size 100 and saving the model weights to my_model.h5:
python examples/intent_extraction/train_enc-dec_model.py \
--embedding_model <path_to_glove_100_file> \
--token_emb_size 100 \
--dataset_path <path_to_data> \
--model_path my_model.h5
To list all possible parameters: python train_joint_model.py/train_enc-dec_model.py -h
Interactive mode
Interactive mode allows to run sentences on a trained model (either of two) and get the results of the models displayed interactively. Example:
python examples/intent_extraction/interactive.py --model_path model.h5 --model_info_path model_info.dat
Results
Results for SNIPS NLU dataset and ATIS are published below. The reference results were taken from the originating paper. Minor differences might occur in final results. Each model was trained for 100 epochs with default parameters.
SNIPS
| Joint task | Encoder-Decoder | |
|---|---|---|
| Slots | 97 | 85.96 |
| Intent | 99.14 |
ATIS
| Joint task | Encoder-Decoder | [1] | [2] | |
|---|---|---|---|---|
| Slots | 95.52 | 93.74 | 95.48 | 95.47 |
| Intent | 96.08 |
Note
We used ATIS [3] [4] dataset from: https://github.com/Microsoft/CNTK/tree/master/Examples/LanguageUnderstanding/ATIS/Data. Intel does not grant any rights to the data files.
References
| [1] | Hakkani-Tur, Dilek and Tur, Gokhan and Celikyilmaz, Asli and Chen, Yun-Nung and Gao, Jianfeng and Deng, Li and Wang, Ye-Yi. Multi-Domain Joint Semantic Frame Parsing using Bi-directional RNN-LSTM. |
| [2] | Gakuto Kurata, Bing Xiang, Bowen Zhou, Mo Yu. Leveraging Sentence-level Information with Encoder LSTM for Semantic Slot Filling. |
| [3] | (1, 2)
|
| [4] | (1, 2)
|
| [5] | Alice Coucke and Alaa Saade and Adrien Ball and Théodore Bluche and Alexandre Caulier and David Leroy and Clément Doumouro and Thibault Gisselbrecht and Francesco Caltagirone and Thibaut Lavril and Maël Primet and Joseph Dureau. Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces. |