Neural Models for Sequence Tagging
Overview
Token tagging is a core Information extraction task in which words (or phrases) are classified using a pre-defined label set. Common core NLP tagging tasks are Word Chunking, Part-of-speech (POS) tagging or Named entity recognition (NER).
Example
Named Entity Recognition (NER) is a basic Information extraction task in which words (or phrases) are classified into pre-defined entity groups (or marked as non interesting). Entity groups share common characteristics of consisting words or phrases and are identifiable by the shape of the word or context in which they appear in sentences. Examples of entity groups are: names, numbers, locations, currency, dates, company names, etc.
Example sentence:
John is planning a visit to London on October
| | |
Name City Date
In this example, a name, city and date entities are identified.
Models
NLP Architect includes the following models:
- Word Chunking
- POS Tagging
- Named Entity Recognition
Word Chunker
Overview
Phrase chunking is a basic NLP task that consists of tagging parts of a sentence (1 or more tokens) syntactically, i.e. POS tagging.
The quick brown fox jumped over the fence
| | | |
Noun Verb Prep Noun
In this example the sentence can be divided into 4 phrases, The quick brown fox and the fence
are noun phrases, jumped is a verb phrase and over is a prepositional phrase.
Dataset
We used the CONLL2000 shared task dataset in our example for training a phrase chunker. More info about the CONLL2000 shared task can be found here: https://www.clips.uantwerpen.be/conll2000/chunking/. The terms and conditions of the data set license apply. Intel does not grant any rights to the data files. The annotation of the data has been derived from the WSJ corpus by a program written by Sabine Buchholz from Tilburg University, The Netherlands.
The CONLL2000 dataset has a train_set and test_set sets consisting of 8926 and 2009 sentences annotated with Part-of-speech and chunking information.
We implemented a dataset loader, CONLL2000, for loading and parsing CONLL2000 data into numpy arrays ready to be used sequential tagging models. For full set of options please see CONLL2000.
NLP Architect has a data loader to easily load CONLL2000 which can be found in CONLL2000. The loader supports the following feature generation when loading the dataset:
- Sentence words in sparse int representation
- Part-of-speech tags of words
- Chunk tag of words (IOB format)
- Characters of sentence words in sparse int representation (optional)
To get the dataset follow these steps:
- download train and test files from dataset website.
- unzip files:
gunzip *.gz - provide
CONLL2000data loader ortrain.pysample below the directory containing the files.
Model
The sequence chunker is a Tensorflow-keras based model and it is implemented in SequenceChunker and comes with several options for creating the topology depending on what input is given (tokens, external word embedding model, topology parameters).
The model is based on the paper: Deep multi-task learning with low level tasks supervised at lower layers by Søgaard and Goldberg (2016), but with minor alterations.
The described model in the paper consists of multiple sequential Bi-directional LSTM layers which are set to predict different tags. the Part-of-speech tags are projected onto a fully connected layer and label tagging is done after the first LSTM layer. The chunk labels are predicted similarly after the 3rd LSTM layer.
The model has additional improvements to the model presented in the paper:
- Choose between Conditional Random Fields (
CRF) classifier instead of ‘softmax’ as the prediction layers. (models using CRF have been empirically shown to produce more accurate predictions) - Character embeddings using CNNs extracting 3-grams - extracting character information out of words was shown to help syntactic tasks such as tagging and chunking.
The model’s embedding vector size and LSTM layer hidden state have equal sizes, the default training optimizer is Adam with default parameters.
Running Modalities
We provide a simple example for training and running inference using the SequenceChunker model.
examples/chunker/train.py will load CONLL2000 dataset and train a model using given training parameters (batch size, epochs, external word embedding, etc.), save the model once done training and print the performance of the model on the test set. The example supports loading GloVe/Fasttext word embedding models to be used when training a model. The training method used in this example trains on both POS and Chunk labels concurrently with equal target loss weights, this is different than what is described in the paper.
examples/chunker/inference.py will load a saved model and a given text file with sentences and print the chunks found on the stdout.
Training
Quick train
Train a model with default parameters (use sentence words and default network settings):
python examples/chunker/train.py --data_dir <path to CONLL2000 files>
Custom training parameters
All customizable parameters can be obtained by running: python train.py -h
| -h, --help | show this help message and exit |
| --data_dir DATA_DIR | |
| Path to directory containing CONLL2000 files | |
| --embedding_model EMBEDDING_MODEL | |
| Word embedding model path (GloVe/Fasttext/textual) | |
| --sentence_length SENTENCE_LENGTH | |
| Maximum sentence length | |
| --char_features | |
| use word character features in addition to words | |
| --max_word_length MAX_WORD_LENGTH | |
| maximum number of character in one word (if –char_features is enabled) | |
| --feature_size FEATURE_SIZE | |
| Feature vector size (in embedding and LSTM layers) | |
| --use_cudnn | use CUDNN based LSTM cells |
- –classifier {crf,softmax}
- classifier to use in last layer
| -b B | batch size |
| -e E | number of epochs run fit model |
| --model_name MODEL_NAME | |
| Model name (used for saving the model) | |
Saving the model after training is done automatically by specifying a model name with the keyword –model_name, the following files will be created:
chunker_model.h5- model filechunker_model.params- model parameter files (topology parameters, vocabs)
Inference
Running inference on a trained model using an input file (text based, each line is a document):
python examples/chunker/inference.py --model_name <model_name> --input <input_file>.txt
Named Entity Recognition
NeuralTagger
A model for training token tagging tasks, such as NER or POS. NeuralTagger requires an embedder for
extracting the contextual features of the data, see embedders below.
The model uses either a Softmax or a Conditional Random Field classifier to classify the words into
correct labels. Implemented in PyTorch and support only PyTorch based embedders.
See NeuralTagger for complete documentation of model methods.
-
class
nlp_architect.models.tagging.NeuralTagger(embedder_model, word_vocab: nlp_architect.utils.text.Vocabulary, labels: List[str] = None, use_crf: bool = False, device: str = 'cpu', n_gpus=0)[source] Simple neural tagging model Supports pytorch embedder models, multi-gpu training, KD from teacher models
Parameters: - embedder_model – pytorch embedder model (valid nn.Module model)
- word_vocab (Vocabulary) – word vocabulary
- labels (List, optional) – list of labels. Defaults to None
- use_crf (bool, optional) – use CRF a the classifier (instead of Softmax). Defaults to False.
- device (str, optional) – device backend. Defatuls to ‘cpu’.
- n_gpus (int, optional) – number of gpus. Default to 0.
CNNLSTM
This module is a embedder based on End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF by Ma and Hovy (2016). The model uses CNNs to embed character representation of words in a sentence and stacked bi-direction LSTM layers to embed the context of words and characters.
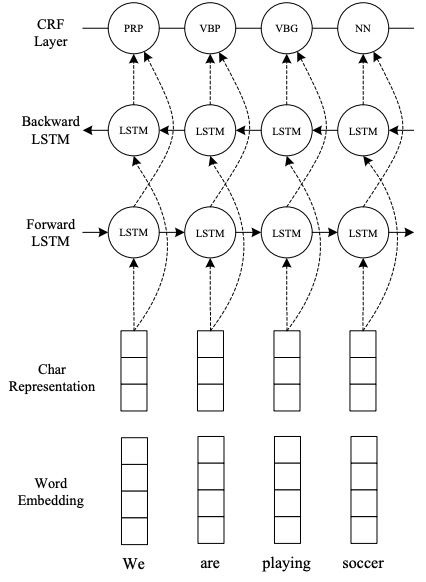
CNN-LSTM topology (taken from original paper)
Usage
Use TokenClsProcessor for parsing input files for the model. NeuralTagger for training/loading a trained model.
Training a model:
nlp-train tagger --model_type cnn-lstm --data_dir <path to data dir> --output_dir <model output dir>
See `nlp-train tagger -h` for full list of options for training.
Running inference on trained model:
nlp-inference tagger --data_file <input data file> --model_dir <model dir> --output_dir <output dir>
See `nlp-inference tagger -h` for full list of options for running a trained model.
-
class
nlp_architect.nn.torch.modules.embedders.CNNLSTM(word_vocab_size: int, num_labels: int, word_embedding_dims: int = 100, char_embedding_dims: int = 16, cnn_kernel_size: int = 3, cnn_num_filters: int = 128, lstm_hidden_size: int = 100, lstm_layers: int = 2, bidir: bool = True, dropout: float = 0.5, padding_idx: int = 0)[source] CNN-LSTM embedder (based on Ma and Hovy. 2016)
Parameters: - word_vocab_size (int) – word vocabulary size
- num_labels (int) – number of labels (classifier)
- word_embedding_dims (int, optional) – word embedding dims
- char_embedding_dims (int, optional) – character embedding dims
- cnn_kernel_size (int, optional) – character CNN kernel size
- cnn_num_filters (int, optional) – character CNN number of filters
- lstm_hidden_size (int, optional) – LSTM embedder hidden size
- lstm_layers (int, optional) – num of LSTM layers
- bidir (bool, optional) – apply bi-directional LSTM
- dropout (float, optional) – dropout rate
- padding_idx (int, optinal) – padding number for embedding layers
IDCNN
The module is an embedder based on Fast and Accurate Entity Recognition with Iterated Dilated Convolutions by Strubell et at (2017). The model uses Iterated-Dilated convolusions for sequence labelling. An dilated CNN block utilizes CNN and dilations to catpure the context of a whole sentence and relation ships between words. In the figure below you can see an example for a dilated CNN block with maximum dilation of 4 and filter width of 3. This model is a fast alternative to LSTM-based models with ~10x speedup compared to LSTM-based models.
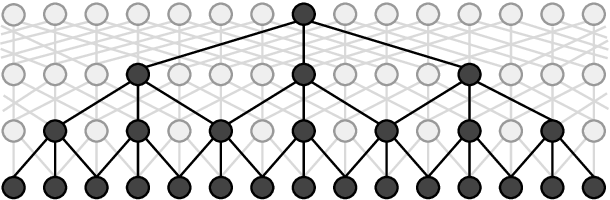
A dilated CNN block (taken from original paper)
We added a word character convolution feature extractor which is concatenated to the embedded word representations.
Usage
Use TokenClsProcessor for parsing input files for the model. NeuralTagger for training/loading a trained model.
Training a model:
nlp-train tagger --model_type id-cnn --data_dir <path to data dir> --output_dir <model output dir>
See `nlp-train tagger -h` for full list of options for training.
Running inference on trained model:
nlp-inference tagger --data_file <input data file> --model_dir <model dir> --output_dir <output dir>
See `nlp-inference tagger -h` for full list of options for running a trained model.
-
class
nlp_architect.nn.torch.modules.embedders.IDCNN(word_vocab_size: int, num_labels: int, word_embedding_dims: int = 100, shape_vocab_size: int = 4, shape_embedding_dims: int = 5, char_embedding_dims: int = 16, char_cnn_filters: int = 128, char_cnn_kernel_size: int = 3, cnn_kernel_size: int = 3, cnn_num_filters: int = 128, input_dropout: float = 0.35, middle_dropout: float = 0, hidden_dropout: float = 0.15, blocks: int = 1, dilations: List = None, embedding_pad_idx: int = 0, use_chars: bool = False, drop_penalty: float = 0.0001)[source] ID-CNN (iterated dilated) tagging model (based on Strubell et al 2017) with word character embedding (using CNN feature extractors)
Parameters: - word_vocab_size (int) – word vocabulary size
- num_labels (int) – number of labels (classifier)
- word_embedding_dims (int, optional) – word embedding dims
- shape_vocab_size (int, optional) – shape vocabulary size
- shape_embedding_dims (int, optional) – shape embedding dims
- char_embedding_dims (int, optional) – character embedding dims
- char_cnn_filters (int, optional) – character CNN kernel size
- char_cnn_kernel_size (int, optional) – character CNN number of filters
- cnn_kernel_size (int, optional) – CNN embedder kernel size
- cnn_num_filters (int, optional) – CNN embedder number of filters
- input_dropout (float, optional) – input layer (embedding) dropout rate
- middle_dropout (float, optional) – middle layer dropout rate
- hidden_dropout (float, optional) – hidden layer dropout rate
- blocks (int, optinal) – number of blocks
- dilations (List, optinal) – List of dilations per CNN layer
- embedding_pad_idx (int, optional) – padding number for embedding layers
- use_chars (bool, optional) – whether to use char embedding, defaults to False
- drop_penalty (float, optional) – penalty for dropout regularization
TransformerTokenClassifier
A tagger using a Transformer-based topology and a pre-trained model on a large collection of data (usually wikipedia and such).
TransformerTokenClassifier We provide token tagging classifier head module for Transformer-based pre-trained models.
Currently we support BERT/XLNet and quantized BERT base models which utilize a fully-connected layer with Softmax classifier. Tokens which were broken into multiple sub-tokens (using Wordpiece algorithm or such) are ignored. For a complete list of transformer base models run `nlp-train transformer_token -h` to see a list of models that can be fine-tuned to your task.
Usage
Use TokenClsProcessor for parsing input files for the model. Depending on which model you choose, the padding and sentence formatting is adjusted to fit the base model you chose.
See model class TransformerTokenClassifier for usage documentation.
Training a model:
nlp-train transformer_token \
--data_dir <path to data> \
--model_name_or_path <name of pre-trained model or path> \
--model_type [bert, quant_bert, xlnet] \
--output_dir <path to output dir>
See `nlp-train transformer_token -h` for full list of options for training.
Running inference on a trained model:
nlp-inference transformer_token \
--data_file <path to input file> \
--model_path <path to trained model> \
--model_type [bert, quant_bert, xlnet] \
--output_dir <output path>
See nlp-inference tagger -h for full list of options for running a trained model.