Distiller design
Distiller is designed to be easily integrated into your own PyTorch research applications.
It is easiest to understand this integration by examining the code of the sample application for compressing image classification models (compress_classifier.py).
The application borrows its main flow code from torchvision's ImageNet classification training sample application (https://github.com/pytorch/examples/tree/master/imagenet). We tried to keep it similar, in order to make it familiar and easy to understand.
Integrating compression is very simple: simply add invocations of the appropriate compression_scheduler callbacks, for each stage in the training. The training skeleton looks like the pseudo code below. The boiler-plate Pytorch classification training is speckled with invocations of CompressionScheduler.
For each epoch:
compression_scheduler.on_epoch_begin(epoch)
train()
validate()
save_checkpoint()
compression_scheduler.on_epoch_end(epoch)
train():
For each training step:
compression_scheduler.on_minibatch_begin(epoch)
output = model(input_var)
loss = criterion(output, target_var)
compression_scheduler.before_backward_pass(epoch)
loss.backward()
optimizer.step()
compression_scheduler.on_minibatch_end(epoch)
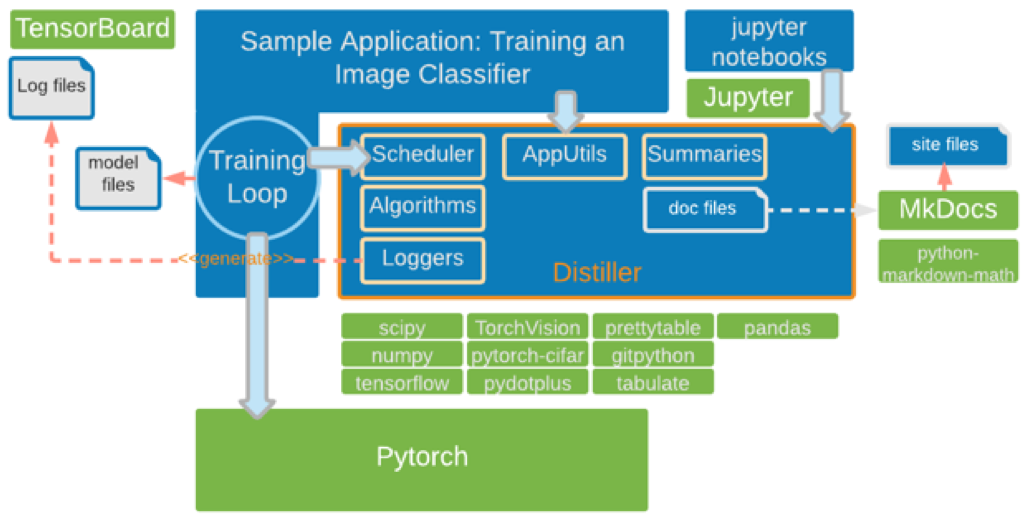
These callbacks can be seen in the diagram below, as the arrow pointing from the Training Loop and into Distiller's Scheduler, which invokes the correct algorithm. The application also uses Distiller services to collect statistics in Summaries and logs files, which can be queried at a later time, from Jupyter notebooks or TensorBoard.
Sparsification and fine-tuning
- The application sets up a model as normally done in PyTorch.
- And then instantiates a Scheduler and configures it:
- Scheduler configuration is defined in a YAML file
- The configuration specifies Policies. Each Policy is tied to a specific algorithm which controls some aspect of the training.
- Some types of algorithms control the actual sparsification of the model. Such types are "pruner" and "regularizer".
- Some algorithms control some parameter of the training process, such as the learning-rate decay scheduler (lr_scheduler).
- The parameters of each algorithm are also specified in the configuration.
- In addition to specifying the algorithm, each Policy specifies scheduling parameters which control when the algorithm is executed: start epoch, end epoch and frequency.
- The Scheduler exposes callbacks for relevant training stages: epoch start/end, mini-batch start/end and pre-backward pass. Each scheduler callback activates the policies that were defined according the schedule that was defined.
- These callbacks are placed the training loop.
Quantization
A quantized model is obtained by replacing existing operations with quantized versions. The quantized versions can be either complete replacements, or wrappers. A wrapper will use the existing modules internally and add quantization and de-quantization operations before/after as necessary.
In Distiller we will provide a set of quantized versions of common operations which will enable implementation of different quantization methods. The user can write a quantized model from scratch, using the quantized operations provided.
We also provide a mechanism which takes an existing model and automatically replaces required operations with quantized versions. This mechanism is exposed by the Quantizer class. Quantizer should be sub-classed for each quantization method.
Model Transformation
The high-level flow is as follows:
- Define a mapping between the module types to be replaced (e.g. Conv2D, Linear, etc.) to a function which generates the replacement module. The mapping is defined in the
replacement_factoryattribute of theQuantizerclass. - Iterate over the modules defined in the model. For each module, if its type is in the mapping, call the replacement generation function. We pass the existing module to this function to allow wrapping of it.
- Replace the existing module with the module returned by the function. It is important to note that the name of the module does not change, as that could break the
forwardfunction of the parent module.
Different quantization methods may, obviously, use different quantized operations. In addition, different methods may employ different "strategies" of replacing / wrapping existing modules. For instance, some methods replace ReLU with another activation function, while others keep it. Hence, for each quantization method, a different mapping will likely be defined.
Each sub-class of Quantizer should populate the replacement_factory dictionary attribute with the appropriate mapping.
To execute the model transformation, call the prepare_model function of the Quantizer instance.
Flexible Bit-Widths
- Each instance of
Quantizeris parameterized by the number of bits to be used for quantization of different tensor types. The default ones are activations and weights. These are thebits_activations,bits_weightsandbits_biasparameters inQuantizer's constructor. Sub-classes may define bit-widths for other tensor types as needed. - We also want to be able to override the default number of bits mentioned in the bullet above for certain layers. These could be very specific layers. However, many models are comprised of building blocks ("container" modules, such as Sequential) which contain several modules, and it is likely we'll want to override settings for entire blocks, or for a certain module across different blocks. When such building blocks are used, the names of the internal modules usually follow some pattern.
- So, for this purpose, Quantizer also accepts a mapping of regular expressions to number of bits. This allows the user to override specific layers using they're exact name, or a group of layers via a regular expression. This mapping is passed via the
overridesparameter in the constructor. - The
overridesmapping is required to be an instance ofcollections.OrderedDict(as opposed to just a simple Pythondict). This is done in order to enable handling of overlapping name patterns.
So, for example, one could define certain override parameters for a group of layers, e.g. 'conv*', but also define different parameters for specific layers in that group, e.g. 'conv1'.
The patterns are evaluated eagerly - the first match wins. Therefore, the more specific patterns must come before the broad patterns.
Weights Quantization
The Quantizer class also provides an API to quantize the weights of all layers at once. To use it, the param_quantization_fn attribute needs to point to a function that accepts a tensor and the number of bits. During model transformation, the Quantizer class will build a list of all model parameters that need to be quantized along with their bit-width. Then, the quantize_params function can be called, which will iterate over all parameters and quantize them using params_quantization_fn.
Quantization-Aware Training
The Quantizer class supports quantization-aware training, that is - training with quantization in the loop. This requires handling of a couple of flows / scenarios:
-
Maintaining a full precision copy of the weights, as described here. This is enabled by setting
train_with_fp_copy=Truein theQuantizerconstructor. At model transformation, in each module that has parameters that should be quantized, a newtorch.nn.Parameteris added, which will maintain the required full precision copy of the parameters. Note that this is done in-place - a new module is not created. We preferred not to sub-class the existing PyTorch modules for this purpose. In order to this in-place, and also guarantee proper back-propagation through the weights quantization function, we employ the following "hack":- The existing
torch.nn.Parameter, e.g.weights, is replaced by atorch.nn.Parameternamedfloat_weight. - To maintain the existing functionality of the module, we then register a
bufferin the module with the original name -weights. - During training,
float_weightwill be passed toparam_quantization_fnand the result will be stored inweight.
- The existing
-
In addition, some quantization methods may introduce additional learned parameters to the model. For example, in the PACT method, acitvations are clipped to a value , which is a learned parameter per-layer
To support these two cases, the Quantizer class also accepts an instance of a torch.optim.Optimizer (normally this would be one an instance of its sub-classes). The quantizer will take care of modifying the optimizer according to the changes made to the parameters.
Optimizing New Parameters
In cases where new parameters are required by the scheme, it is likely that they'll need to be optimized separately from the main model parameters. In that case, the sub-class for the speicifc method should override Quantizer._get_updated_optimizer_params_groups(), and return the proper groups plus any desired hyper-parameter overrides.
Examples
The base Quantizer class is implemented in distiller/quantization/quantizer.py.
For a simple sub-class implementing symmetric linear quantization, see SymmetricLinearQuantizer in distiller/quantization/range_linear.py.
In distiller/quantization/clipped_linear.py there are examples of lower-precision methods which use training with quantization. Specifically, see PACTQuantizer for an example of overriding Quantizer._get_updated_optimizer_params_groups().