Named Entity Recognition
NeuralTagger
A model for training token tagging tasks, such as NER or POS. NeuralTagger requires an embedder for
extracting the contextual features of the data, see embedders below.
The model uses either a Softmax or a Conditional Random Field classifier to classify the words into
correct labels. Implemented in PyTorch and support only PyTorch based embedders.
See NeuralTagger for complete documentation of model methods.
-
class
nlp_architect.models.tagging.NeuralTagger(embedder_model, word_vocab: nlp_architect.utils.text.Vocabulary, labels: List[str] = None, use_crf: bool = False, device: str = 'cpu', n_gpus=0)[source] Simple neural tagging model Supports pytorch embedder models, multi-gpu training, KD from teacher models
Parameters: - embedder_model – pytorch embedder model (valid nn.Module model)
- word_vocab (Vocabulary) – word vocabulary
- labels (List, optional) – list of labels. Defaults to None
- use_crf (bool, optional) – use CRF a the classifier (instead of Softmax). Defaults to False.
- device (str, optional) – device backend. Defatuls to ‘cpu’.
- n_gpus (int, optional) – number of gpus. Default to 0.
CNNLSTM
This module is a embedder based on End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF by Ma and Hovy (2016). The model uses CNNs to embed character representation of words in a sentence and stacked bi-direction LSTM layers to embed the context of words and characters.
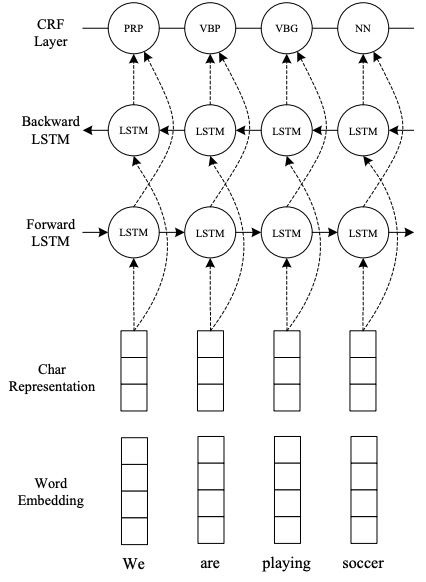
CNN-LSTM topology (taken from original paper)
Usage
Use TokenClsProcessor for parsing input files for the model. NeuralTagger for training/loading a trained model.
Training a model:
nlp-train tagger --model_type cnn-lstm --data_dir <path to data dir> --output_dir <model output dir>
See `nlp-train tagger -h` for full list of options for training.
Running inference on trained model:
nlp-inference tagger --data_file <input data file> --model_dir <model dir> --output_dir <output dir>
See `nlp-inference tagger -h` for full list of options for running a trained model.
-
class
nlp_architect.nn.torch.modules.embedders.CNNLSTM(word_vocab_size: int, num_labels: int, word_embedding_dims: int = 100, char_embedding_dims: int = 16, cnn_kernel_size: int = 3, cnn_num_filters: int = 128, lstm_hidden_size: int = 100, lstm_layers: int = 2, bidir: bool = True, dropout: float = 0.5, padding_idx: int = 0)[source] CNN-LSTM embedder (based on Ma and Hovy. 2016)
Parameters: - word_vocab_size (int) – word vocabulary size
- num_labels (int) – number of labels (classifier)
- word_embedding_dims (int, optional) – word embedding dims
- char_embedding_dims (int, optional) – character embedding dims
- cnn_kernel_size (int, optional) – character CNN kernel size
- cnn_num_filters (int, optional) – character CNN number of filters
- lstm_hidden_size (int, optional) – LSTM embedder hidden size
- lstm_layers (int, optional) – num of LSTM layers
- bidir (bool, optional) – apply bi-directional LSTM
- dropout (float, optional) – dropout rate
- padding_idx (int, optinal) – padding number for embedding layers
IDCNN
The module is an embedder based on Fast and Accurate Entity Recognition with Iterated Dilated Convolutions by Strubell et at (2017). The model uses Iterated-Dilated convolusions for sequence labelling. An dilated CNN block utilizes CNN and dilations to catpure the context of a whole sentence and relation ships between words. In the figure below you can see an example for a dilated CNN block with maximum dilation of 4 and filter width of 3. This model is a fast alternative to LSTM-based models with ~10x speedup compared to LSTM-based models.
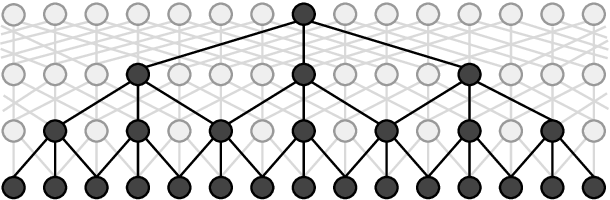
A dilated CNN block (taken from original paper)
We added a word character convolution feature extractor which is concatenated to the embedded word representations.
Usage
Use TokenClsProcessor for parsing input files for the model. NeuralTagger for training/loading a trained model.
Training a model:
nlp-train tagger --model_type id-cnn --data_dir <path to data dir> --output_dir <model output dir>
See `nlp-train tagger -h` for full list of options for training.
Running inference on trained model:
nlp-inference tagger --data_file <input data file> --model_dir <model dir> --output_dir <output dir>
See `nlp-inference tagger -h` for full list of options for running a trained model.
-
class
nlp_architect.nn.torch.modules.embedders.IDCNN(word_vocab_size: int, num_labels: int, word_embedding_dims: int = 100, shape_vocab_size: int = 4, shape_embedding_dims: int = 5, char_embedding_dims: int = 16, char_cnn_filters: int = 128, char_cnn_kernel_size: int = 3, cnn_kernel_size: int = 3, cnn_num_filters: int = 128, input_dropout: float = 0.35, middle_dropout: float = 0, hidden_dropout: float = 0.15, blocks: int = 1, dilations: List = None, embedding_pad_idx: int = 0, use_chars: bool = False, drop_penalty: float = 0.0001)[source] ID-CNN (iterated dilated) tagging model (based on Strubell et al 2017) with word character embedding (using CNN feature extractors)
Parameters: - word_vocab_size (int) – word vocabulary size
- num_labels (int) – number of labels (classifier)
- word_embedding_dims (int, optional) – word embedding dims
- shape_vocab_size (int, optional) – shape vocabulary size
- shape_embedding_dims (int, optional) – shape embedding dims
- char_embedding_dims (int, optional) – character embedding dims
- char_cnn_filters (int, optional) – character CNN kernel size
- char_cnn_kernel_size (int, optional) – character CNN number of filters
- cnn_kernel_size (int, optional) – CNN embedder kernel size
- cnn_num_filters (int, optional) – CNN embedder number of filters
- input_dropout (float, optional) – input layer (embedding) dropout rate
- middle_dropout (float, optional) – middle layer dropout rate
- hidden_dropout (float, optional) – hidden layer dropout rate
- blocks (int, optinal) – number of blocks
- dilations (List, optinal) – List of dilations per CNN layer
- embedding_pad_idx (int, optional) – padding number for embedding layers
- use_chars (bool, optional) – whether to use char embedding, defaults to False
- drop_penalty (float, optional) – penalty for dropout regularization
TransformerTokenClassifier
A tagger using a Transformer-based topology and a pre-trained model on a large collection of data (usually wikipedia and such).
TransformerTokenClassifier We provide token tagging classifier head module for Transformer-based pre-trained models.
Currently we support BERT/XLNet and quantized BERT base models which utilize a fully-connected layer with Softmax classifier. Tokens which were broken into multiple sub-tokens (using Wordpiece algorithm or such) are ignored. For a complete list of transformer base models run `nlp-train transformer_token -h` to see a list of models that can be fine-tuned to your task.
Usage
Use TokenClsProcessor for parsing input files for the model. Depending on which model you choose, the padding and sentence formatting is adjusted to fit the base model you chose.
See model class TransformerTokenClassifier for usage documentation.
Training a model:
nlp-train transformer_token \
--data_dir <path to data> \
--model_name_or_path <name of pre-trained model or path> \
--model_type [bert, quant_bert, xlnet] \
--output_dir <path to output dir>
See `nlp-train transformer_token -h` for full list of options for training.
Running inference on a trained model:
nlp-inference transformer_token \
--data_file <path to input file> \
--model_path <path to trained model> \
--model_type [bert, quant_bert, xlnet] \
--output_dir <output path>
See nlp-inference tagger -h for full list of options for running a trained model.