Behavioral Cloning¶
Actions space: Discrete | Continuous
Network Structure¶
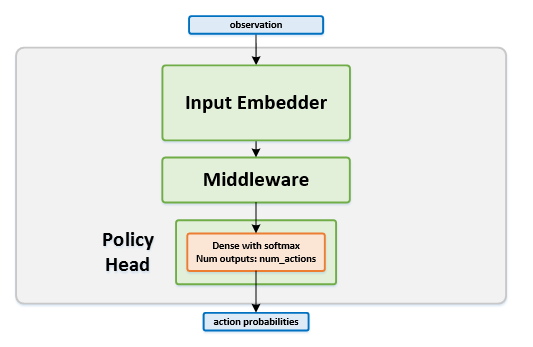
Algorithm Description¶
Training the network¶
The replay buffer contains the expert demonstrations for the task. These demonstrations are given as state, action tuples, and with no reward. The training goal is to reduce the difference between the actions predicted by the network and the actions taken by the expert for each state.
Sample a batch of transitions from the replay buffer.
Use the current states as input to the network, and the expert actions as the targets of the network.
For the network head, we use the policy head, which uses the cross entropy loss function.