Actor-Critic¶
Actions space: Discrete | Continuous
References: Asynchronous Methods for Deep Reinforcement Learning
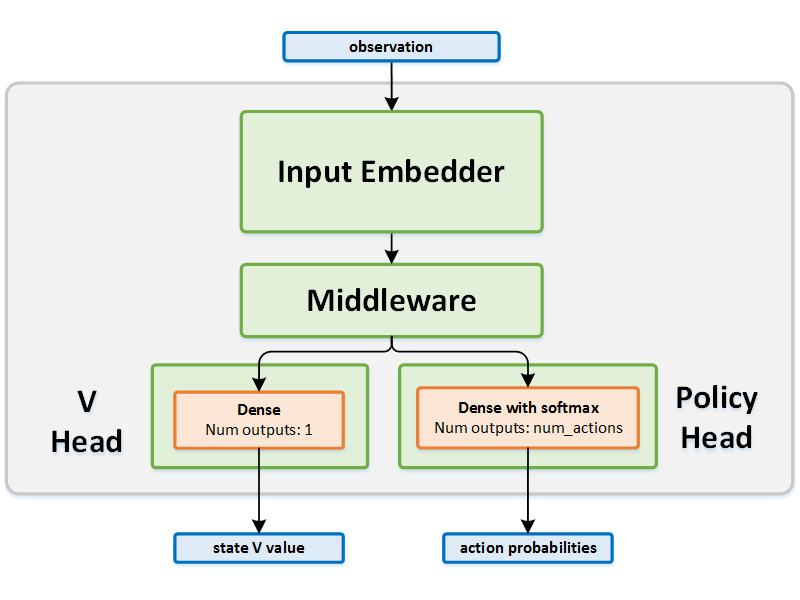
Network Structure¶
Algorithm Description¶
Choosing an action - Discrete actions¶
The policy network is used in order to predict action probabilites. While training, a sample is taken from a categorical distribution assigned with these probabilities. When testing, the action with the highest probability is used.
Training the network¶
A batch of \(T_{max}\) transitions is used, and the advantages are calculated upon it.
Advantages can be calculated by either of the following methods (configured by the selected preset) -
A_VALUE - Estimating advantage directly: \(A(s_t, a_t) = \underbrace{\sum_{i=t}^{i=t + k - 1} \gamma^{i-t}r_i +\gamma^{k} V(s_{t+k})}_{Q(s_t, a_t)} - V(s_t)\) where \(k\) is \(T_{max} - State\_Index\) for each state in the batch.
GAE - By following the Generalized Advantage Estimation paper.
The advantages are then used in order to accumulate gradients according to \(L = -\mathop{\mathbb{E}} [log (\pi) \cdot A]\)
-
class
rl_coach.agents.actor_critic_agent.ActorCriticAlgorithmParameters[source]¶ - Parameters
policy_gradient_rescaler – (PolicyGradientRescaler) The value that will be used to rescale the policy gradient
apply_gradients_every_x_episodes – (int) The number of episodes to wait before applying the accumulated gradients to the network. The training iterations only accumulate gradients without actually applying them.
beta_entropy – (float) The weight that will be given to the entropy regularization which is used in order to improve exploration.
num_steps_between_gradient_updates – (int) Every num_steps_between_gradient_updates transitions will be considered as a single batch and use for accumulating gradients. This is also the number of steps used for bootstrapping according to the n-step formulation.
gae_lambda – (float) If the policy gradient rescaler was defined as PolicyGradientRescaler.GAE, the generalized advantage estimation scheme will be used, in which case the lambda value controls the decay for the different n-step lengths.
estimate_state_value_using_gae – (bool) If set to True, the state value targets for the V head will be estimated using the GAE scheme.