Direct Future Prediction¶
Actions space: Discrete
References: Learning to Act by Predicting the Future
Network Structure¶
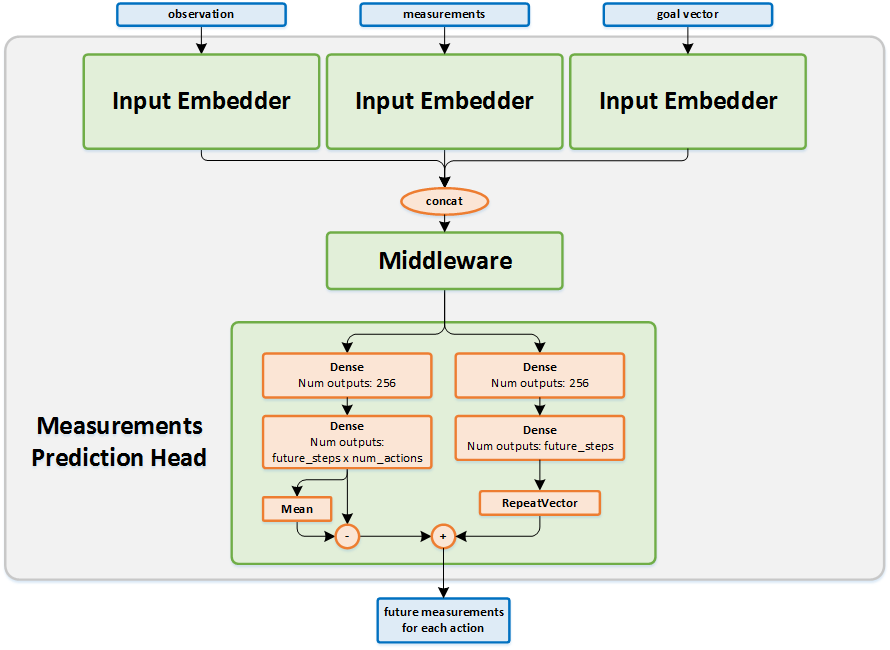
Algorithm Description¶
Choosing an action¶
The current states (observations and measurements) and the corresponding goal vector are passed as an input to the network. The output of the network is the predicted future measurements for time-steps \(t+1,t+2,t+4,t+8,t+16\) and \(t+32\) for each possible action.
For each action, the measurements of each predicted time-step are multiplied by the goal vector, and the result is a single vector of future values for each action.
Then, a weighted sum of the future values of each action is calculated, and the result is a single value for each action.
The action values are passed to the exploration policy to decide on the action to use.
Training the network¶
Given a batch of transitions, run them through the network to get the current predictions of the future measurements per action, and set them as the initial targets for training the network. For each transition \((s_t,a_t,r_t,s_{t+1} )\) in the batch, the target of the network for the action that was taken, is the actual measurements that were seen in time-steps \(t+1,t+2,t+4,t+8,t+16\) and \(t+32\). For the actions that were not taken, the targets are the current values.
-
class
rl_coach.agents.dfp_agent.DFPAlgorithmParameters[source]¶ - Parameters
num_predicted_steps_ahead – (int) Number of future steps to predict measurements for. The future steps won’t be sequential, but rather jump in multiples of 2. For example, if num_predicted_steps_ahead = 3, then the steps will be: t+1, t+2, t+4. The predicted steps will be [t + 2**i for i in range(num_predicted_steps_ahead)]
goal_vector – (List[float]) The goal vector will weight each of the measurements to form an optimization goal. The vector should have the same length as the number of measurements, and it will be vector multiplied by the measurements. Positive values correspond to trying to maximize the particular measurement, and negative values correspond to trying to minimize the particular measurement.
future_measurements_weights – (List[float]) The future_measurements_weights weight the contribution of each of the predicted timesteps to the optimization goal. For example, if there are 6 steps predicted ahead, and a future_measurements_weights vector with 3 values, then only the 3 last timesteps will be taken into account, according to the weights in the future_measurements_weights vector.
use_accumulated_reward_as_measurement – (bool) If set to True, the accumulated reward from the beginning of the episode will be added as a measurement to the measurements vector in the state. This van be useful in environments where the given measurements don’t include enough information for the particular goal the agent should achieve.
handling_targets_after_episode_end – (HandlingTargetsAfterEpisodeEnd) Dictates how to handle measurements that are outside the episode length.
scale_measurements_targets – (Dict[str, float]) Allows rescaling the values of each of the measurements available. This van be useful when the measurements have a different scale and you want to normalize them to the same scale.