Dueling DQN¶
Actions space: Discrete
References: Dueling Network Architectures for Deep Reinforcement Learning
Network Structure¶
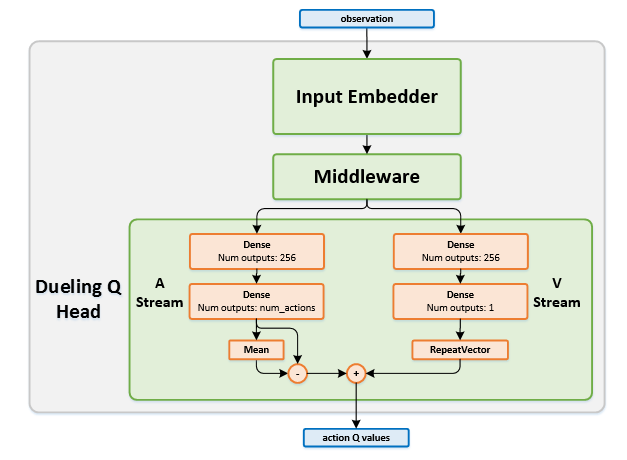
General Description¶
Dueling DQN presents a change in the network structure comparing to DQN.
Dueling DQN uses a specialized Dueling Q Head in order to separate \(Q\) to an \(A\) (advantage) stream and a \(V\) stream. Adding this type of structure to the network head allows the network to better differentiate actions from one another, and significantly improves the learning.
In many states, the values of the different actions are very similar, and it is less important which action to take. This is especially important in environments where there are many actions to choose from. In DQN, on each training iteration, for each of the states in the batch, we update the :ath:`Q` values only for the specific actions taken in those states. This results in slower learning as we do not learn the \(Q\) values for actions that were not taken yet. On dueling architecture, on the other hand, learning is faster - as we start learning the state-value even if only a single action has been taken at this state.