ACER¶
Actions space: Discrete
References: Sample Efficient Actor-Critic with Experience Replay
Network Structure¶
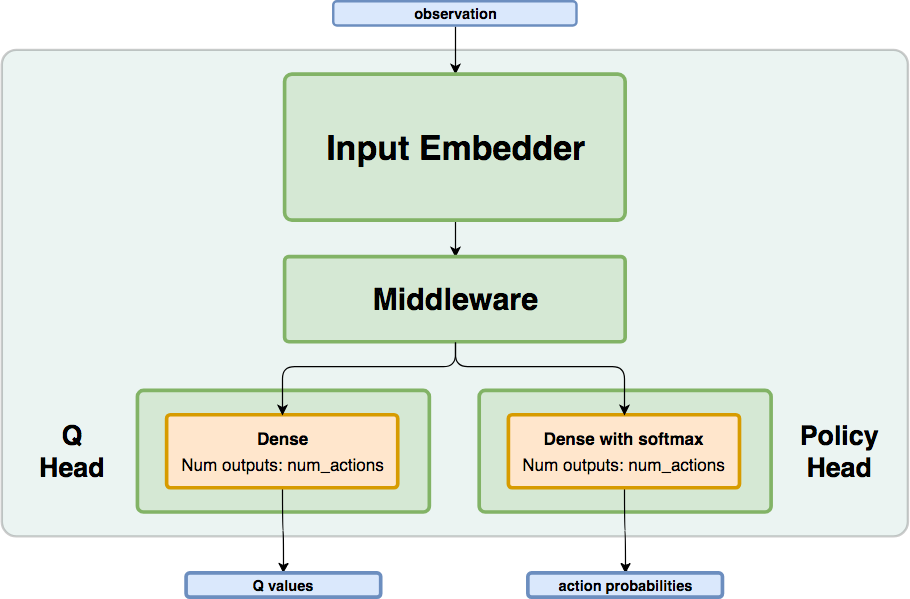
Algorithm Description¶
Choosing an action - Discrete actions¶
The policy network is used in order to predict action probabilites. While training, a sample is taken from a categorical distribution assigned with these probabilities. When testing, the action with the highest probability is used.
Training the network¶
Each iteration perform one on-policy update with a batch of the last \(T_{max}\) transitions, and \(n\) (replay ratio) off-policy updates from batches of \(T_{max}\) transitions sampled from the replay buffer.
Each update perform the following procedure:
Calculate state values:
\[V(s_t) = \mathbb{E}_{a \sim \pi} [Q(s_t,a)]\]Calculate Q retrace:
\[Q^{ret}(s_t,a_t) = r_t +\gamma \bar{\rho}_{t+1}[Q^{ret}(s_{t+1},a_{t+1}) - Q(s_{t+1},a_{t+1})] + \gamma V(s_{t+1})\]\[\text{where} \quad \bar{\rho}_{t} = \min{\left\{c,\rho_t\right\}},\quad \rho_t=\frac{\pi (a_t \mid s_t)}{\mu (a_t \mid s_t)}\]Accumulate gradients:
\(\bullet\) Policy gradients (with bias correction):
\[\begin{split}\hat{g}_t^{policy} & = & \bar{\rho}_{t} \nabla \log \pi (a_t \mid s_t) [Q^{ret}(s_t,a_t) - V(s_t)] \\ & & + \mathbb{E}_{a \sim \pi} \left(\left[\frac{\rho_t(a)-c}{\rho_t(a)}\right] \nabla \log \pi (a \mid s_t) [Q(s_t,a) - V(s_t)] \right)\end{split}\]\(\bullet\) Q-Head gradients (MSE):
\[\begin{split}\hat{g}_t^{Q} = (Q^{ret}(s_t,a_t) - Q(s_t,a_t)) \nabla Q(s_t,a_t)\\\end{split}\](Optional) Trust region update: change the policy loss gradient w.r.t network output:
\[\hat{g}_t^{trust-region} = \hat{g}_t^{policy} - \max \left\{0, \frac{k^T \hat{g}_t^{policy} - \delta}{\lVert k \rVert_2^2}\right\} k\]\[\text{where} \quad k = \nabla D_{KL}[\pi_{avg} \parallel \pi]\]The average policy network is an exponential moving average of the parameters of the network (\(\theta_{avg}=\alpha\theta_{avg}+(1-\alpha)\theta\)). The goal of the trust region update is to the difference between the updated policy and the average policy to ensure stability.
-
class
rl_coach.agents.acer_agent.ACERAlgorithmParameters[source]¶ - Parameters
num_steps_between_gradient_updates – (int) Every num_steps_between_gradient_updates transitions will be considered as a single batch and use for accumulating gradients. This is also the number of steps used for bootstrapping according to the n-step formulation.
ratio_of_replay – (int) The number of off-policy training iterations in each ACER iteration.
num_transitions_to_start_replay – (int) Number of environment steps until ACER starts to train off-policy from the experience replay. This emulates a heat-up phase where the agents learns only on-policy until there are enough transitions in the experience replay to start the off-policy training.
rate_for_copying_weights_to_target – (float) The rate of the exponential moving average for the average policy which is used for the trust region optimization. The target network in this algorithm is used as the average policy.
importance_weight_truncation – (float) The clipping constant for the importance weight truncation (not used in the Q-retrace calculation).
use_trust_region_optimization – (bool) If set to True, the gradients of the network will be modified with a term dependant on the KL divergence between the average policy and the current one, to bound the change of the policy during the network update.
max_KL_divergence – (float) The upper bound parameter for the trust region optimization, use_trust_region_optimization needs to be set true for this parameter to have an effect.
beta_entropy – (float) An entropy regulaization term can be added to the loss function in order to control exploration. This term is weighted using the beta value defined by beta_entropy.