Quantile Regression DQN¶
Actions space: Discrete
References: Distributional Reinforcement Learning with Quantile Regression
Network Structure¶
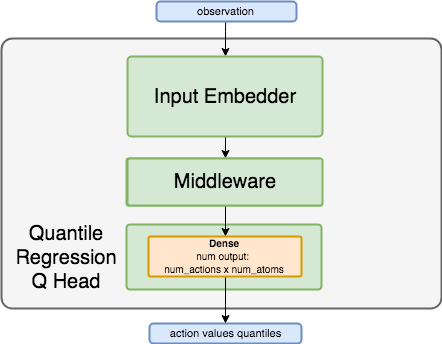
Algorithm Description¶
Training the network¶
Sample a batch of transitions from the replay buffer.
First, the next state quantiles are predicted. These are used in order to calculate the targets for the network, by following the Bellman equation. Next, the current quantile locations for the current states are predicted, sorted, and used for calculating the quantile midpoints targets.
The network is trained with the quantile regression loss between the resulting quantile locations and the target quantile locations. Only the targets of the actions that were actually taken are updated.
Once in every few thousand steps, weights are copied from the online network to the target network.
-
class
rl_coach.agents.qr_dqn_agent.QuantileRegressionDQNAlgorithmParameters[source]¶ - Parameters
atoms – (int) the number of atoms to predict for each action
huber_loss_interval – (float) One of the huber loss parameters, and is referred to as \(\kapa\) in the paper. It describes the interval [-k, k] in which the huber loss acts as a MSE loss.