Categorical DQN¶
Actions space: Discrete
References: A Distributional Perspective on Reinforcement Learning
Network Structure¶
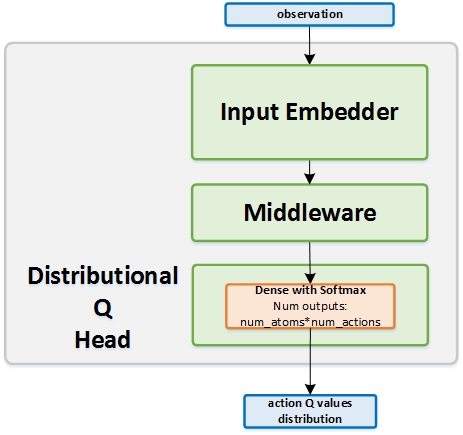
Algorithm Description¶
Training the network¶
Sample a batch of transitions from the replay buffer.
The Bellman update is projected to the set of atoms representing the \(Q\) values distribution, such that the \(i-th\) component of the projected update is calculated as follows:
\((\Phi \hat{T} Z_{\theta}(s_t,a_t))_i=\sum_{j=0}^{N-1}\Big[1-\frac{\lvert[\hat{T}_{z_{j}}]^{V_{MAX}}_{V_{MIN}}-z_i\rvert}{\Delta z}\Big]^1_0 \ p_j(s_{t+1}, \pi(s_{t+1}))\)
where: * \([ \cdot ]\) bounds its argument in the range \([a, b]\) * \(\hat{T}_{z_{j}}\) is the Bellman update for atom \(z_j\): \(\hat{T}_{z_{j}} := r+\gamma z_j\)
Network is trained with the cross entropy loss between the resulting probability distribution and the target probability distribution. Only the target of the actions that were actually taken is updated.
Once in every few thousand steps, weights are copied from the online network to the target network.
-
class
rl_coach.agents.categorical_dqn_agent.CategoricalDQNAlgorithmParameters[source]¶ - Parameters
v_min – (float) The minimal value that will be represented in the network output for predicting the Q value. Corresponds to \(v_{min}\) in the paper.
v_max – (float) The maximum value that will be represented in the network output for predicting the Q value. Corresponds to \(v_{max}\) in the paper.
atoms – (int) The number of atoms that will be used to discretize the range between v_min and v_max. For the C51 algorithm described in the paper, the number of atoms is 51.