Conditional Imitation Learning¶
Actions space: Discrete | Continuous
References: End-to-end Driving via Conditional Imitation Learning
Network Structure¶
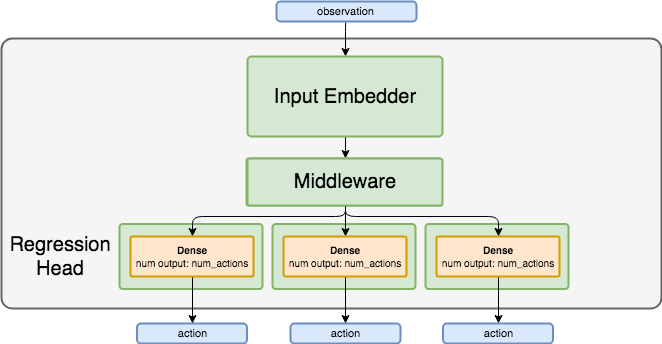
Algorithm Description¶
Training the network¶
The replay buffer contains the expert demonstrations for the task. These demonstrations are given as state, action tuples, and with no reward. The training goal is to reduce the difference between the actions predicted by the network and the actions taken by the expert for each state. In conditional imitation learning, each transition is assigned a class, which determines the goal that was pursuit in that transitions. For example, 3 possible classes can be: turn right, turn left and follow lane.
Sample a batch of transitions from the replay buffer, where the batch is balanced, meaning that an equal number of transitions will be sampled from each class index.
Use the current states as input to the network, and assign the expert actions as the targets of the network heads corresponding to the state classes. For the other heads, set the targets to match the currently predicted values, so that the loss for the other heads will be zeroed out.
We use a regression head, that minimizes the MSE loss between the network predicted values and the target values.