Neural Episodic Control¶
Actions space: Discrete
References: Neural Episodic Control
Network Structure¶
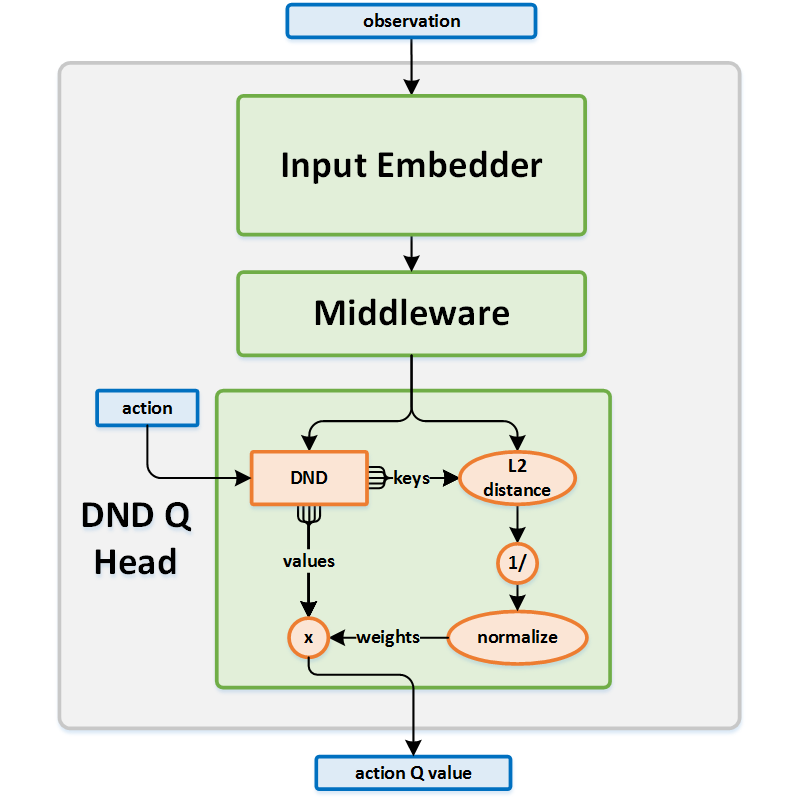
Algorithm Description¶
Choosing an action¶
Use the current state as an input to the online network and extract the state embedding, which is the intermediate output from the middleware.
For each possible action \(a_i\), run the DND head using the state embedding and the selected action \(a_i\) as inputs. The DND is queried and returns the \(P\) nearest neighbor keys and values. The keys and values are used to calculate and return the action \(Q\) value from the network.
Pass all the \(Q\) values to the exploration policy and choose an action accordingly.
Store the state embeddings and actions taken during the current episode in a small buffer \(B\), in order to accumulate transitions until it is possible to calculate the total discounted returns over the entire episode.
Finalizing an episode¶
For each step in the episode, the state embeddings and the taken actions are stored in the buffer \(B\). When the episode is finished, the replay buffer calculates the \(N\)-step total return of each transition in the buffer, bootstrapped using the maximum \(Q\) value of the \(N\)-th transition. Those values are inserted along with the total return into the DND, and the buffer \(B\) is reset.
Training the network¶
Train the network only when the DND has enough entries for querying.
To train the network, the current states are used as the inputs and the \(N\)-step returns are used as the targets. The \(N\)-step return used takes into account \(N\) consecutive steps, and bootstraps the last value from the network if necessary: \(y_t=\sum_{j=0}^{N-1}\gamma^j r(s_{t+j},a_{t+j} ) +\gamma^N max_a Q(s_{t+N},a)\)
-
class
rl_coach.agents.nec_agent.NECAlgorithmParameters[source]¶ - Parameters
dnd_size – (int) Defines the number of transitions that will be stored in each one of the DNDs. Note that the total number of transitions that will be stored is dnd_size x num_actions.
l2_norm_added_delta – (float) A small value that will be added when calculating the weight of each of the DND entries. This follows the \(\delta\) patameter defined in the paper.
new_value_shift_coefficient – (float) In the case where a ew embedding that was added to the DND was already present, the value that will be stored in the DND is a mix between the existing value and the new value. The mix rate is defined by new_value_shift_coefficient.
number_of_knn – (int) The number of neighbors that will be retrieved for each DND query.
DND_key_error_threshold – (float) When the DND is queried for a specific embedding, this threshold will be used to determine if the embedding exists in the DND, since exact matches of embeddings are very rare.
propagate_updates_to_DND – (bool) If set to True, when the gradients of the network will be calculated, the gradients will also be backpropagated through the keys of the DND. The keys will then be updated as well, as if they were regular network weights.
n_step – (int) The bootstrap length that will be used when calculating the state values to store in the DND.
bootstrap_total_return_from_old_policy – (bool) If set to True, the bootstrap that will be used to calculate each state-action value, is the network value when the state was first seen, and not the latest, most up-to-date network value.