Bootstrapped DQN¶
Actions space: Discrete
References: Deep Exploration via Bootstrapped DQN
Network Structure¶
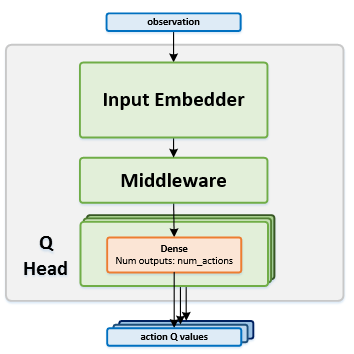
Algorithm Description¶
Choosing an action¶
The current states are used as the input to the network. The network contains several $Q$ heads, which are used for returning different estimations of the action \(Q\) values. For each episode, the bootstrapped exploration policy selects a single head to play with during the episode. According to the selected head, only the relevant output \(Q\) values are used. Using those \(Q\) values, the exploration policy then selects the action for acting.
Storing the transitions¶
For each transition, a Binomial mask is generated according to a predefined probability, and the number of output heads. The mask is a binary vector where each element holds a 0 for heads that shouldn’t train on the specific transition, and 1 for heads that should use the transition for training. The mask is stored as part of the transition info in the replay buffer.
Training the network¶
First, sample a batch of transitions from the replay buffer. Run the current states through the network and get the current \(Q\) value predictions for all the heads and all the actions. For each transition in the batch, and for each output head, if the transition mask is 1 - change the targets of the played action to \(y_t\), according to the standard DQN update rule:
\(y_t=r(s_t,a_t )+\gamma\cdot max_a Q(s_{t+1},a)\)
Otherwise, leave it intact so that the transition does not affect the learning of this head. Then, train the online network according to the calculated targets.
As in DQN, once in every few thousand steps, copy the weights from the online network to the target network.