N-Step Q Learning¶
Actions space: Discrete
References: Asynchronous Methods for Deep Reinforcement Learning
Network Structure¶
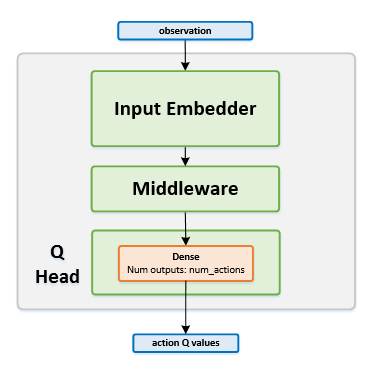
Algorithm Description¶
Training the network¶
The \(N\)-step Q learning algorithm works in similar manner to DQN except for the following changes:
No replay buffer is used. Instead of sampling random batches of transitions, the network is trained every \(N\) steps using the latest \(N\) steps played by the agent.
In order to stabilize the learning, multiple workers work together to update the network. This creates the same effect as uncorrelating the samples used for training.
Instead of using single-step Q targets for the network, the rewards from $N$ consequent steps are accumulated to form the \(N\)-step Q targets, according to the following equation: \(R(s_t, a_t) = \sum_{i=t}^{i=t + k - 1} \gamma^{i-t}r_i +\gamma^{k} V(s_{t+k})\) where \(k\) is \(T_{max} - State\_Index\) for each state in the batch
-
class
rl_coach.agents.n_step_q_agent.NStepQAlgorithmParameters[source]¶ - Parameters
num_steps_between_copying_online_weights_to_target – (StepMethod) The number of steps between copying the online network weights to the target network weights.
apply_gradients_every_x_episodes – (int) The number of episodes between applying the accumulated gradients to the network. After every num_steps_between_gradient_updates steps, the agent will calculate the gradients for the collected data, it will then accumulate it in internal accumulators, and will only apply them to the network once in every apply_gradients_every_x_episodes episodes.
num_steps_between_gradient_updates – (int) The number of steps between calculating gradients for the collected data. In the A3C paper, this parameter is called t_max. Since this algorithm is on-policy, only the steps collected between each two gradient calculations are used in the batch.
targets_horizon – (str) Should be either ‘N-Step’ or ‘1-Step’, and defines the length for which to bootstrap the network values over. Essentially, 1-Step follows the regular 1 step bootstrapping Q learning update. For more information, please refer to the original paper (https://arxiv.org/abs/1602.01783)