Normalized Advantage Functions¶
Actions space: Continuous
References: Continuous Deep Q-Learning with Model-based Acceleration
Network Structure¶
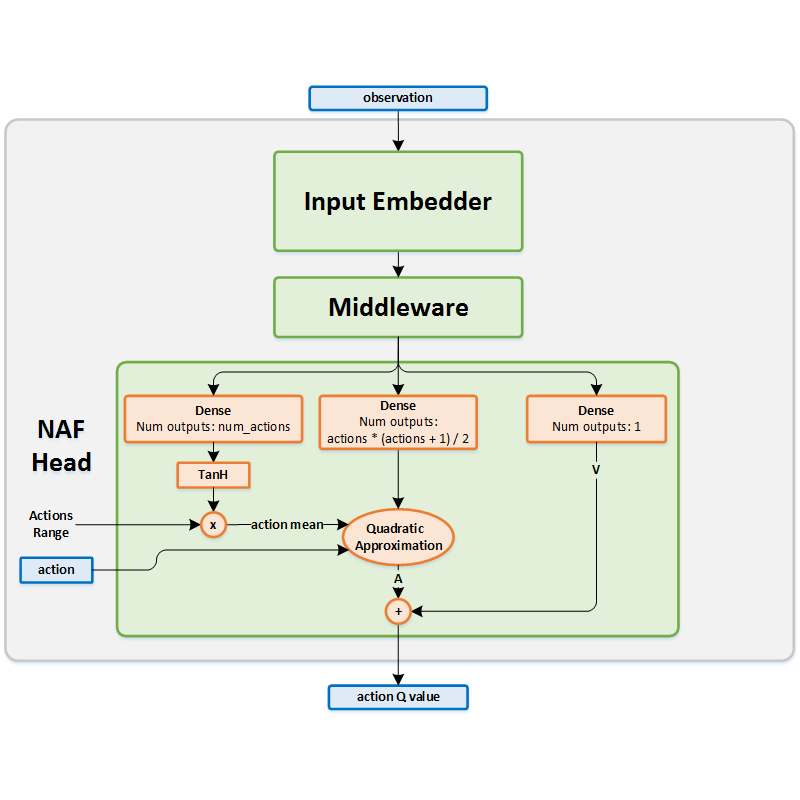
Algorithm Description¶
Choosing an action¶
The current state is used as an input to the network. The action mean \(\mu(s_t )\) is extracted from the output head. It is then passed to the exploration policy which adds noise in order to encourage exploration.
Training the network¶
The network is trained by using the following targets: \(y_t=r(s_t,a_t )+\gamma\cdot V(s_{t+1})\) Use the next states as the inputs to the target network and extract the \(V\) value, from within the head, to get \(V(s_{t+1} )\). Then, update the online network using the current states and actions as inputs, and \(y_t\) as the targets. After every training step, use a soft update in order to copy the weights from the online network to the target network.