Soft Actor-Critic¶
Actions space: Continuous
References: Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Network Structure¶
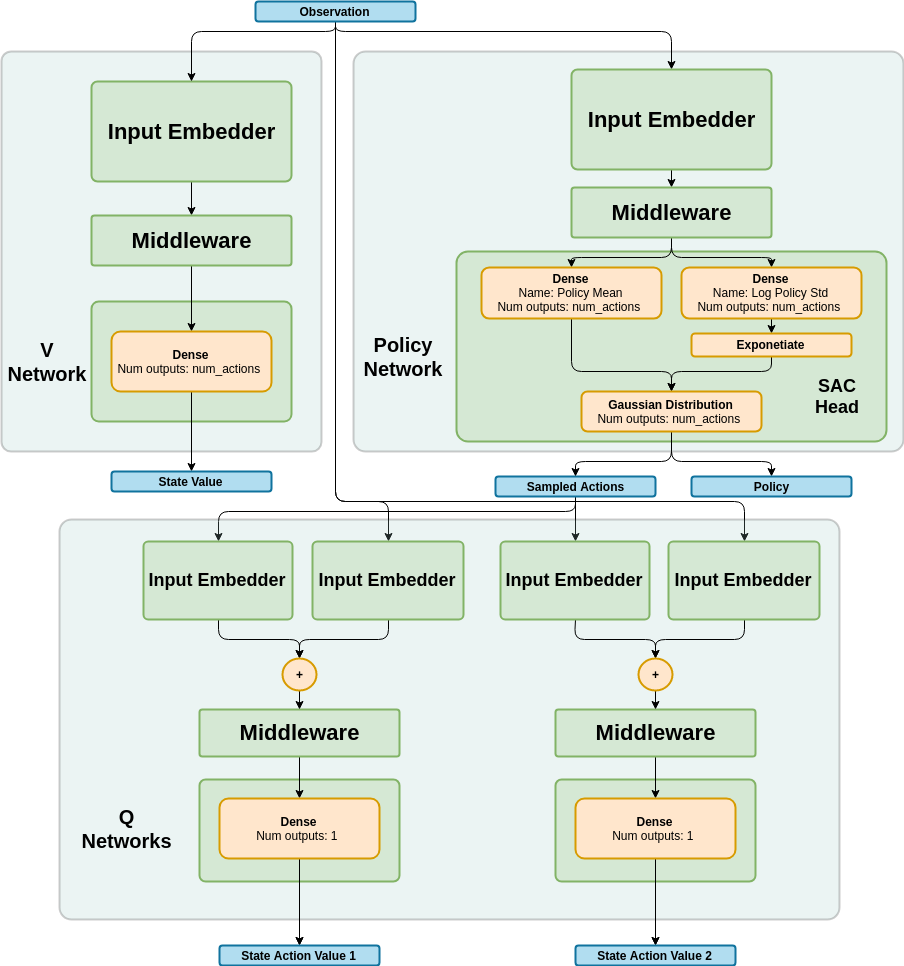
Algorithm Description¶
Choosing an action - Continuous actions¶
The policy network is used in order to predict mean and log std for each action. While training, a sample is taken from a Gaussian distribution with these mean and std values. When testing, the agent can choose deterministically by picking the mean value or sample from a gaussian distribution like in training.
Training the network¶
Start by sampling a batch \(B\) of transitions from the experience replay.
To train the Q network, use the following targets:
\[y_t^Q=r(s_t,a_t)+\gamma \cdot V(s_{t+1})\]The state value used in the above target is acquired by running the target state value network.
To train the State Value network, use the following targets:
\[y_t^V = \min_{i=1,2}Q_i(s_t,\tilde{a}) - log\pi (\tilde{a} \vert s),\,\,\,\, \tilde{a} \sim \pi(\cdot \vert s_t)\]The state value network is trained using a sample-based approximation of the connection between and state value and state action values, The actions used for constructing the target are not sampled from the replay buffer, but rather sampled from the current policy.
To train the actor network, use the following equation:
\[\nabla_{\theta} J \approx \nabla_{\theta} \frac{1}{\vert B \vert} \sum_{s_t\in B} \left( Q \left(s_t, \tilde{a}_\theta(s_t)\right) - log\pi_{\theta}(\tilde{a}_{\theta}(s_t)\vert s_t) \right),\,\,\,\, \tilde{a} \sim \pi(\cdot \vert s_t)\]
After every training step, do a soft update of the V target network’s weights from the online networks.
-
class
rl_coach.agents.soft_actor_critic_agent.SoftActorCriticAlgorithmParameters[source]¶ - Parameters
num_steps_between_copying_online_weights_to_target – (StepMethod) The number of steps between copying the online network weights to the target network weights.
rate_for_copying_weights_to_target – (float) When copying the online network weights to the target network weights, a soft update will be used, which weight the new online network weights by rate_for_copying_weights_to_target. (Tau as defined in the paper)
use_deterministic_for_evaluation – (bool) If True, during the evaluation phase, action are chosen deterministically according to the policy mean and not sampled from the policy distribution.